基于CUDA的itti显著视觉模型
专业:软件工程 学号:201211004 姓名:陶瑞
指导老师:李世伟(讲师)
摘 要:图像的显著性检测广泛应用于图形图像处理领域的各个领域,ITTI就是其中一种优秀的算法,它是属于机器视觉与生物视觉互相结合技术的一种。从图片的亮度、颜色值、方向以及梯度维度分析和提取显著区域。但其运算时间复杂度较高,本文依托CUDA来使用GPU加速ITTI算法的计算流程,使得ITTI的算法模型有了实质的可用性。
关键字:ITTI, CUDA, GPU编程
1 引言
随着机器学习领域的崛起,机器视觉领域越发火热,机器视觉就相当于人的眼睛,代替人的眼睛去工作。所以本文所涉及的算法以及优化,就是这样一个方向。
ITTI算法就是一个用机器视觉的方法去识别类似于人眼的看图的效果 ,去寻找图像中较为明显的区域,主要是通过颜色(红,绿,蓝),色差,亮度,方向,梯度这些信息,达到生物视觉的效果。它计算的复杂度很高,涉及复杂的矩阵运算。同时,维度分离存在了大量可以并行计算的部分,所以如何提高算法的效率对于实际的可用性用较为有效的影响。对于提高ITTI算法的效率,本文使用CUDA接口编程并行计算。
2 ITTI算法流程
ITTI是一种模拟普通生物体视觉注意机制的一种选择性注意模型。在颜色、亮度、方向和周边进行比对形成色差,所有点的显著值就构成一张显著的直方图。ITTI对输入图像首先提取多个特征通道和多尺度并对每个特征分解九层金字塔,再经过几次滤波得到各个维度的特征图,最后将特征图融合成最后结果。
算法实现步骤如下:
1图像读取,使用opencv库提供的imread读取图像数据。并将图像数据存放在Mat中保存。
2维度提取,分离出R,G,B,亮度Y,I(方向及其他)。计算亮度值,同样可以根据r,g,b去获得,根据亮度计算公式2.1。
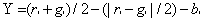 (2.1)
(2.1)
计算得到亮度矩阵Y。同时计算出,其他特征的基础矩阵I
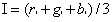 (2.2)
(2.2)
3高斯滤波,使用openCV自带的gaussblur,手写高斯过滤器。nSigma的大小会影响滤波效果,同时高斯核的大小也会影响滤波的效果。nSigma的值取1.6对图像滤波。
4金字塔模型生成,对图片进行稀疏化,生成九层高斯。
5特征差值生成,根据生成的金子塔模型,对不同层的矩阵进行比对,产生一定的差值。这个差值越大则表示这点的特征越明显。
6颜色特征处理,对于RGBY的处理不同于矩阵I的处理,根据颜色学下的拮抗反应,颜色间做差值处理从而生成联合的颜色特征。通过2.3可获得颜色特征值。
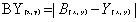
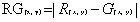 (2.3)
(2.3)
7方向梯度特征维度,方向梯度维度特征使用Gabor滤波生成,对四个方向的特征维度进行提取,分别是0°,45°,90°,135°分别进行滤波,需要生成Gabor核。
8梯度与维度特征融合,对于梯度特征融合,主要分为三个部分,首先要寻找局部最大点Max,以及局部最大点的个数Num,算出平均值Avg。维度特征融合求出平均值即可。
3 CUDA编程加速
3.1 原始图片读取与拷贝到显存
对于图片的读取,这是文件的I/O操作所以必须放在CPU一端,同样利用OpenCV读取图片,将三原色读进内存。
对于已经读取进内存的数据,如果要放在GPU上处理,可以分为三个步骤去处理,首先分配显存,再者进行内存拷贝,最后处理数据,分配显存过程和CPU分配内存过程类似,其中cudaMalloc相当于c下面的malloc函数,对应free也有cudaFree,需要注意的是在这里malloc的函数需要及时的释放,显卡没有回收显存的机制会导致显卡奔溃不工作。cudaMalloc可以方便的传入一个指针地址,这里是一个引用,会被赋值,即为显存中的地址,是一个64位的地址。分配的显存大小和穿进去的第二个数有关,这里制定了和图片大小相同的尺寸,便于计算。
分配好显存大小之后就是拷贝工作,从内存中拷贝到显存中,CUDA给我们提供了很多可以使用的拷贝函数,其中CUDAMemcpy2D,就是说传递一个矩阵到显存,就是传递一个二维数组,而CUDAMemcpy则是传递一个一维数组,但实际上CUDAMencpy可以传递一切维度的数组,根据运算规则可以将任意维度的数组转化为一维数据使用,相对于CUDAMemcpy拷贝CUDAMemcpy2D的拷贝效率更高效一点,因为数据比较规整,是块拷贝,但是CUDAMemcpy2D的传参稍微复杂一点,要指定行数,同时要指定一行的宽度大小,还要指定高度信息,而CUDAMemcpy只要指定拷贝的大小就可以实现拷贝操作,所以在比较规则的数据拷贝时使用CUDAMemcpy2D,简单数据拷贝使用CUDAMemcpy。对于这里的最后一个参数CUDAMemcpyHostToDevice表示从host端传递到device端,即从CPU拷贝到GPU,同样存在从GPU拷回的情况,即该参数为CUDAMemcpyDeviceToHost。
3.2 GPU上处理特征分离
特征分离一个典型的并行度比较高的操作,所以用CUDA优化是有必要的,这里要提取出来R,G,B,Y,I信息。
对于已经在显存的数据,首先要启动GPU运行,还要指定好并行度
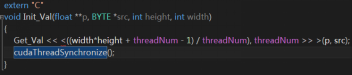
图3.1 启动CUDA线程
这里Get_Val就是启动函数,“<<<...>>>”内指定并行度,threadNum即为每个block启动多少线程,610m可以支持512个线程,在实际测试的过程中不是所有给的线程数越多速度越快,是一定的优化指数在影响运行的速度,而(width*height + threadNum - 1) / threadNum)则表示分配多少线程块去运行这个处理逻辑,而threadNum是每个线程快上执行多少的线程,项目中采用的是每个线程块256个显线程。
对于每个线程来说每个显线程来说处理的逻辑都是相同的,不同的线程所在位置不同,而正是由于线程的位置不同,所以处理的时候就可以根据位置index去选择线程自身要处理的逻辑。在处理颜色,灰度及亮度时可以很自然的发现,每个像素的处理方式都是相同,通过idx索引去获取对应线程信息,其中idx即为线程所在位置,blockIdx.x和blockDim.x分别表示block位置和block中设置的每个block的线程个数,threadId.x表示当前block对应的位置信息,所以根据位置信息可以很好的拿到每个像素对应的位置,idxG即为每个像素的起始位置,进而得到当前位置的要处理的像素,便可以得到当前像素的r,g,b,再根据特征提取公式,提取R,G,B,Y,I信息,数据缓存在显存之中。
3.3 数据缓存策略
做显卡计算最大可以优化性能的地方就是减少内存到显存的交换,同时要提高并行度。
减少内存交换的方法就是申请供程序使用的空间,作为缓存空间,所有的计算结果在显存中放一块干净的区域作为缓存数据,另一方面,维护好这部分空间,在二次使用的时候可以直接用,另一方面就是内存位置,如果使用一些高频数据,例如高斯核数据,在滤波时,每一个线程都会使用到高斯核,对于这样高频数据,可以将其加载到share memery,相当于cache住了,但是share memery只对block内部可见[4],所以每个block都要加载一次,是通过线程内去加载,通过__shared__定义。
提高并行度,要从CUDA程序的内存设计入手,程序并行要设计好每个线程处理的位置,切不干扰其他线程处理的结果。
ITTI算法的过程中有很多可以并行处理,包括特征处理的时的差值提取,包括Gabor滤波,包括数据每一步的高斯滤波等等,不同维度的特征,处理方法很相似,尤其是进行到维度分离之后,所以设计出合适的显存模式对结果的影响是很大的,为了达到程序优化切程序的可读性,提出显存中三级指针的概念。
三级指针申请和拷贝较为复杂,所以在申请的时候要做好地址拷贝,先拿二级指针举例

图3.2 GPU二级指针操作
图3.2中。p为要保存的地址指针,通过循环生成9个图片大小的空间,并将地址放在p[0]-p[8],然后再对显存申请9个地址空间大小的区域p_dev,再将p的内容拷贝进p_dev中,最终的p_dev即为申请好的二级指针在显存中。
更进一步,显存三级指针空间稍微复杂一点,在做显存数据缓存时会用到三级指针,基本逻辑是相同的,首先要申请实际计算空间区域,再对将这些空间得到p_tmp1[i],里面保存的是二维地址,然后再复制地址等比例大小的空间,将p_tmp1[i]的数据复制进显存,这样最终得到p_dev2即为三维的指针数组,对于后续的计算有了很大的便利性。
3.4数据拷回策略
根据ITTI的算法特征,要求出最大值和计算出平均值,这对于并行程序是很难做到的,如果是单纯的直方图统计,可以尝试用CUDA自带原子操作去累计,但是这里的寻找最大值,没有办法做到写同一个变量,会产生冲突,而且线程间事无法通信的,这也是并行程序的通病,为了规避这样的问题,程序在这里做一次拷回策略,本地计算出局部最大值,同时找出局部最大点的个数,需要进行一次拷回,通过cudamencpyDeviceToHost完成。CPU中算出最大值,平均值以及最大点个数之后,再进行一次拷贝,将最大值写回显存,由cudamencpyHostToDevice完成,这样显存中就有了每一个维度特征上最大值,平均值。
4 CPU与GPU耗时对比
图4.1分别是CPU和GPU运行时间情况
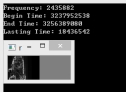
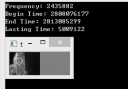
图4.1 CPU和GPU运行时间
其中Frequency表示晶振频率,Begin Time表示当定时器开始时间,End Time表示结束时间,Lasting Time表示程序耗时情况,从两幅图的对比情况看,CPU上好使18.4秒,而GPU上5秒,有将近四倍的性能优化。其他性能比对,图4.1是在CPU为i5-3240m,GPU为GTX610m上进行。对硬件进行升级到i7-4620和GTX960上,分别作图4.2和图4.3实验

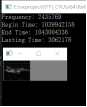
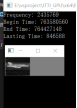

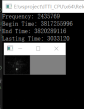
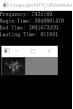
图4.2 比对组一 图4.3 比对组二
通过图4.2和4.3分别对应原图,CPU运行图,GPU运行图,效果上差距不大,时间效率上还是有着近四倍的差距。以上图片都是基于1024*768的像素,图4.5针对图4.3组进行放大一倍,即2048*1536,从结果上来看,效率优化是比较明显的,CPU有12秒多的耗时,而GPU只有1.3秒的耗时,近9倍的效果,图片大小对于优化的效果比较明显。表4.1就是几组实验的测试对比
表4.1 显著算法对比实验
序号 |
CPU |
GPU |
图片大小 |
CPU耗时 |
GPU耗时 |
1 |
i5-3240 |
GTX610 |
1024*768 |
18.4s |
5s |
2 |
i7-4620 |
GTX960 |
1024*768 |
3.06s |
0.84s |
3 |
i7-4620 |
GTX960 |
1024*768 |
3.03s |
0.811s |
4 |
i7-4620 |
GTX960 |
2048*1536 |
12.46s |
1.38s |
通过表4.1数据分析,在GPU下itti算法模型,加速效果明显,对小图片的处理提升了近4倍的效率,对大图片的处理提升了近9倍的效率,达到实验预期的效果。
参考文献
[1] Itti L, Koch C, Niebur E. A model of saliencybased visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(11):1254−1259
[2] 张菁, 沈兰荪, 等. 基于视觉感知的图像检索的研究[J]. 电子学报, 2008, 36(3): 494-499.
[3] (美)Shane Cook:CUDA并行程序设计:GPU编程指南:机械工业出版社(苏统华译)
 甘公网安备62010502000995号 陇ICP备14001560号-2 设计制作 宏点网络
甘公网安备62010502000995号 陇ICP备14001560号-2 设计制作 宏点网络
